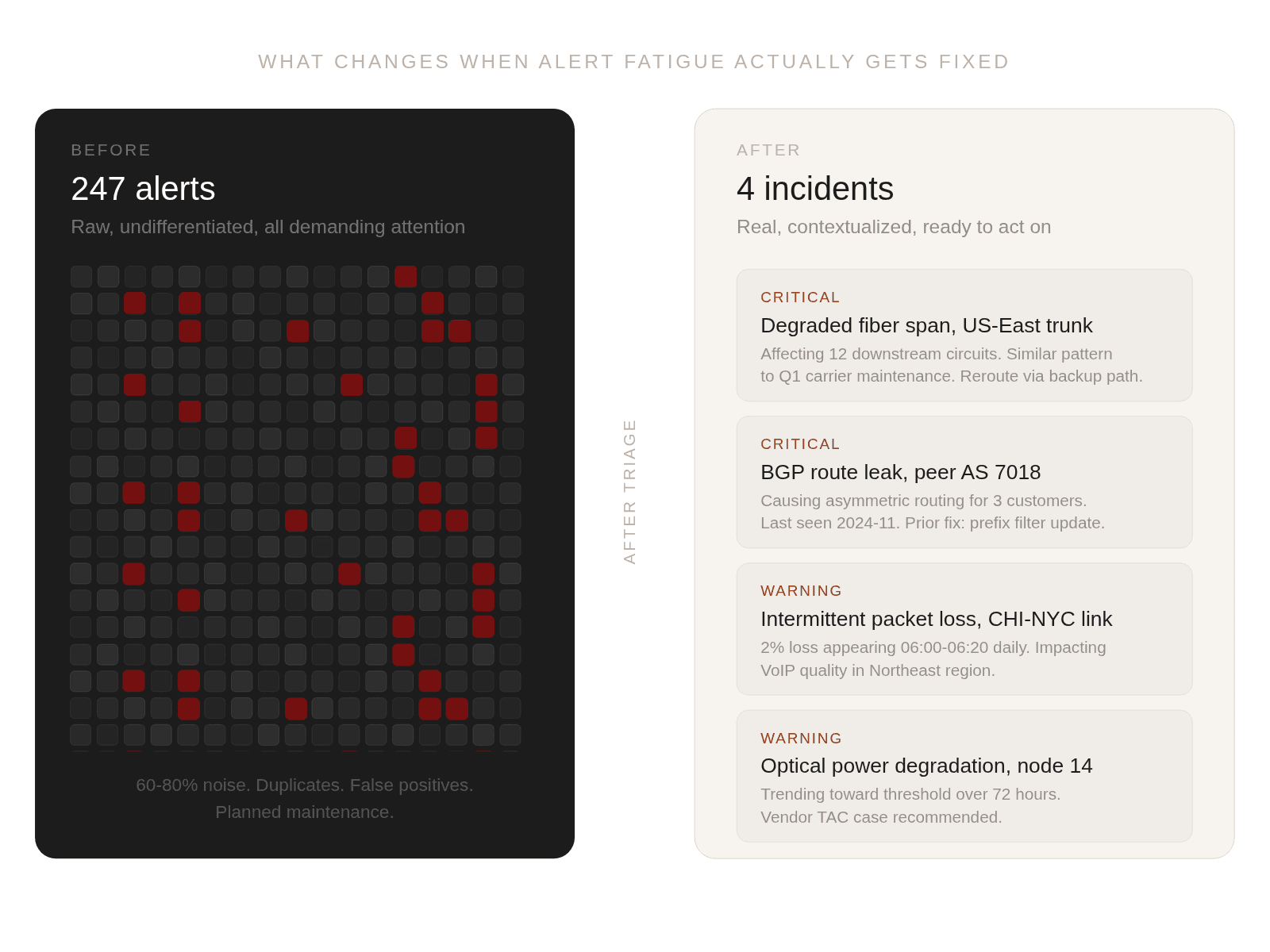
- 60-80% of network alerts are noise, and no amount of hiring fixes that
- Triage, diagnosis, and action: three layers most teams haven't built
- Trust in automation is earned incrementally, not assumed from day one
Back
Alert Fatigue Has a Fix but Most Teams Aren't Building It
Mahir KalraJUNE 11, 2026
Industry
Internet Service Providers (ISP)
Network Scale
Alert Fatigue Has a Fix but Most Teams Aren't Building It
Alert fatigue isn't a discipline problem or a staffing problem. When 60 to 80 percent of your alerts are noise, you can't train or hire your way to a better outcome, because the system itself has to change. And while the problem is well understood by most network operations teams, the fix is less obvious than it should be.
Three Layers of a Real Fix
Solving alert fatigue at the systems level requires three capabilities working together. Most organizations have built pieces of the first, but very few have all three.
The first layer is automated triage. This is the intake layer, where the system classifies incoming alerts, correlates them against live network topology, and filters out duplicates, false positives, and planned maintenance windows before they ever reach a human. The goal is to reduce the queue from hundreds of alerts down to the handful that represent real, actionable incidents. Some teams have built partial versions of this with custom scripting or rule-based engines, but those approaches tend to break down as networks scale and failure modes evolve beyond what static rules can anticipate.
The second layer is contextual diagnosis. When an alert does represent something real, the system needs to do more than flag it. It needs to reason across topology, time, and historical incidents to surface a probable root cause with the relevant context already assembled. That means going beyond "this link is down" to something more like "this link is down, it's affecting these downstream services, we saw a similar pattern during last quarter's carrier maintenance, and here's what resolved it then." This is the layer that replaces the 30-minute manual investigation that currently eats the majority of an incident's lifecycle.
The third layer is the ability to act on what it finds. This is where most approaches stop short. A system that triages and diagnoses but then hands everything back to a human for execution still leaves your team doing repetitive remediation work on well-understood failure modes. What actually moves the needle is a system that can execute known fixes for known patterns (rerouting traffic around a degraded link, closing out a ticket that matches a maintenance window, escalating a novel failure with full diagnostic context) while keeping the operator in control of where that boundary sits.
The Trust Question
If you've operated networks at scale, you're probably skeptical of that third layer, and you should be. The blast radius of a bad automated decision at Layer 2 or Layer 3 is not forgiving. A misconfigured BGP policy doesn't just throw an error in a log; it can black-hole traffic for thousands of customers in seconds.
So the question isn't really whether AI should be trusted to act on network infrastructure. The more useful question is how that trust gets built over time.
The answer comes down to transparency and incremental scope. The operator needs to see what the system considered, why it reached a conclusion, and exactly where its authority starts and stops. In practice, that means starting with low-risk, high-frequency scenarios where the failure mode is well understood and the remediation is routine. As the system proves reliability in those cases, the boundary of what it handles independently can expand, but that expansion should always be controlled by the people who understand the network rather than assumed from day one.
When the reasoning is visible and the safeguards are real, the conversation naturally shifts from "should I trust this" to "where should I let this run."
Why This Is Hard to Build
There's a reason most teams default to buying another dashboard instead of building this. Reasoning about network state is a fundamentally different problem than application-layer observability. It requires understanding topology, path dependencies, device-level behavior, and how failures cascade across physical infrastructure. The tools that dominate the observability market today were built for Layers 4 through 7. They treat the network as an abstraction, and you can't bolt on physical-layer intelligence after the fact.
Building a system that can triage, diagnose, and act at the network layer requires starting from the network up, not from the application down. That's a harder path to take, but it's the only one that actually addresses the root of the problem.
Where This Leads
The point of all this isn't to remove engineers from the loop. It's to make the loop worth being in. When the repetitive triage and diagnosis work is handled before it reaches your team, the engineers who remain are spending their time on the high-value work that drew them to the field in the first place: solving novel problems, making judgment calls, and improving the network itself.
That's how you break the alert fatigue cycle, and it's how you hold onto the people who are best equipped to run your network.
Transform your network operations
Book a demo today